Robots.txt — что это?
Файл robots.txt служит для:

Файл robots.txt можно найти по адресу: domen.ru/robots.txt. Он расположен в корневом каталоге сайта и открывается по данной ссылке. Например, путь до robots.txt нашего сайта выглядит так: https://eurobyte.ru/robots.txt.
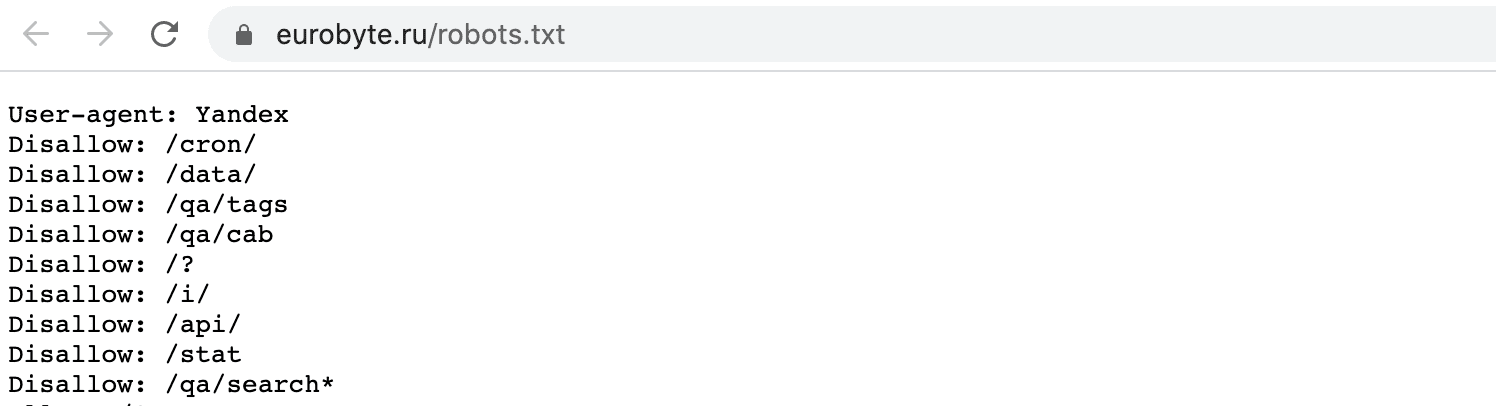
У ПС существуют особые требования к файлу robots.txt. Например, требования от Яндекса:
Требования поисковой системы Google:
Чтобы тестовый вариант сайта не попал в поисковые системы, закройте его от индексации. Создайте файл robots.txt со следующим содержанием:
User-agent: *
Disallow: /
Так выглядит запрет на индексацию всех страниц сайта.
Файл состоит из списка правил (директив), которые указывают поисковым роботам, какие страницы сайта нужно добавлять в индекс, а какие нет. Ниже мы расскажем об основных директивах файла.
Директива User-agent позволяет задать разные правила обхода сайта для разных приложений. Например, если вы установите правило User-agent: YandexBot, то эти правила будут обрабатываться только основным индексирующим роботом Яндекса. User-agent: * задает правила для всех роботов. Однако, если обнаружена строка User-agent: Yandex, то строка User-agent: * не учитывается Яндексом. Выглядит эта директива так:
User-agent: *
Disallow — директива, запрещающая индексацию страниц (например, технических разделов, страниц поиска по сайту, дубликатов). Например:
User-agent: *
Disallow: / # не разрешает обход всего сайта
User-agent: *
Disallow: /product # не допускает обход страниц, адрес которых начинается с /product
Директива Allow напротив допускает индексирование разделов или отдельных страниц веб-ресурса. Например:
User-agent: *
Allow: /catalog
Disallow: /
# не разрешает скачивать все, кроме страниц начинающихся с /catalog
Директива Sitemap указывает путь до специальной карты сайта sitemap.xml. Если на вашем проекте предусмотрено несколько файлов sitemap.xml, то указывайте путь до каждого. Например:
User-agent: *
Allow: /
Sitemap: https://site.ru/sitemap.xml
Таким образом, файл robots.txt позволяет управлять попадаем в индекс ПС страниц вашего веб-сайта. Помните, что для поисковой системы Google правила, описанные в этом файле, не являются строгими. Подробнее о правильном составлении robots.txt вы можете прочитать в справках Яндекса и Google. Если у вас остались вопросы, задавайте их в комментариях. Спасибо, что дочитали!
Автор: ЕвробайтПоделиться



Sitemap.xml — это специальный файл, где собраны все ссылки на страницы сайта, которые следует проиндексировать в поисковых системах (ПС), например, в Яндекс или Google.

Факторы ранжирования — это совокупность факторов и признаков, по которым поисковые системы понимают, на каком месте должна отображаться страница сайта в поисковой выдаче.

Реферальный маркетинг — это инструмент для продвижения продукта или услуги с помощью реальных людей.
Надёжные VPS серверы с посуточной оплатой в России и Европе.
От 10 ₽ в день!
Арендовать виртуальный сервер





